Collective Intelligence
1 El Farol Bar Problem
- Agents try to decide which night of the week they should go
to El Farol Bar.
- Each agent makes an independent decision at the beginning of
the week.
- The agents have the best time if there are c agents in the
bar that night.
- Lets say the agents use reinforcement learning to learn
which night is best. If we, as system designers, want to
maximize the sum of all agent utilities, what reward function
should we use?
- The agent gets a reward based on how many agents where
there on the night it attended?
- On the nights he did not attend?
- Something else?
- COllective INtelligence (COIN) tries to answer this question
for the general case.
2 COIN Framework
- The goal is to find local utility functions for the agents
such that the global utility is maximized, assuming the agents
are using reinforcement learning.
- It has three main components:
- Defines equivalence classes of local utility functions
such that if they increase so does the global utility.
- Further restricts the allowable utility functions such
that agents do not frustrate each other by lowering
others' utility. The design for these first two is the COIN
initialization.
- Modify the local utility functions at runtime based on
localized statistical information in order to better align
them to the global.
- Microlearning refers to each agent's reinforcement
learning.
- Macrolearning refers to the modification of each
agent's utility function (step 3).
3 Notation
- Sn,t is the state of agent n at time t.
- S is the state of all agents across all time.
- G(S) is the world utility.
- Subworlds are sets of agents that make up an
exhaustive partition of all agents.
- For each subworld w, all agents in it have the same
subworld utility functions gw(S)
- At one extreme each agent could be its own
subworld.
- A constraint-aligned system is one in which any
change to the state of the agents in subworld w at time 0 will
have no effect on the state of agents outside of w at times
later than 0. (rarely happens).
- A subworld-factored is one where a change at time 0
to the agents in w results in an increased vale for
gw(S) if and only if it results in an
increased value for G(S).
- The wonderful life utility (WL) for all agents in w
is defined as G(S) - G(CLw(S)) where
CLw(S) is the vector S modified by clamping the
states of all agents in w, across all time, to an arbitrary
fixed value (0).
- We can view it as the change in world utility has w not existed.
- It is purely mathematical. No assumption is being made
that CLw(S) could ever happen.
- A constraint-aligned system with wonderful life subworld
utilities is subworld-factored and, the authors have shown,
will approach near-optimal values of the world
utility!
- Of course, constraint-aligned systems are very rare, so
experiments are needed to determine how well WL performs under a
not-so-aligned system.
4 Bar Experiment
- We define the G(S) to be the sum over all time of the the
utilities that all the agents received for their actions. That
is
- G(S) = SUMt SUMk=1..t lk(xk(S,t))
where xk(S,t) is the number of agents that attended
on night k at week t and lk(y) =
ak*y*exp(-y/c) is the utility that is derived from
that attendance. This function is maximized when y=c.
- Two different choices for ak were explored. One
were attendance on all nights is equally weighted and one were
we are only concerned with attendance on one specific night.
- Three different reward functions were tested (where
dw is the night selected by w).
- Uniform Division reward UD = ldw(xdw(S,t))/xdw(S,t)
- Global reward GR = SUMk=1..7 lk(xk(S,t))
- Wonderful Life reward WL = ldw(xdw(S,t)) - ldw(xdw(CLw(S),t))
- Each agent is in its own subworld.
- The microlearning algorithms used is a basic reinforcement
algorithm with Boltzmann stochastic decisions.
5 Results
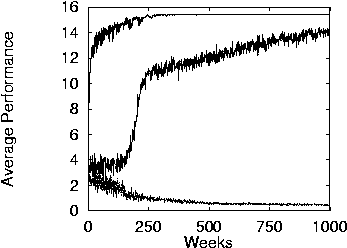
- Performance when only one night is considered. Top curve is WL, middle is GR, and bottom is UD.
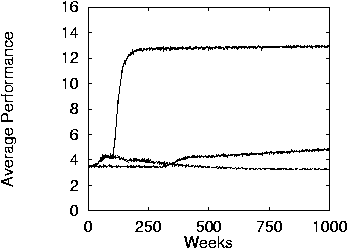
- Performance when all nights are considered.
- WL converges to optimal much faster than GR. UD does not converge. It is an instance of the tragedy of the commons.
- Even without being constrained aligned, the system performs
better with WL.
6 Leader Follower Problem
- We try to make the problem harder for WL and add the use of
macrolearning.
- In this experiment macrolearning consists of changing the
subworld memberships of the agents. Each subworld has three
agents.
- In this problem each leader has two followers. The two
followers should pick the same night as the leader.
- Macrolearning is used after 500 weeks. At that time
correlations are found between agents attendance and the most
correlated are placed in the same subworld.
7 Results
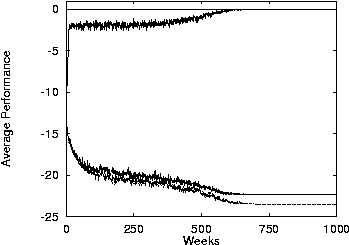
- Performance in leader-follower problem with a worst-case
payoff matrix---the leader maximizes his WL reward when his is
placed in separate subworld from followers.
- The top curve represents perfect constraint alignment in the
initial subworld-assignment (i.e., leader and followers in the
same subworld), the bottom minimal constraint-alignment (i.e.,
leader and followers in different subworlds), and the middle
random subworld assignments.
- There is no macrolearning.
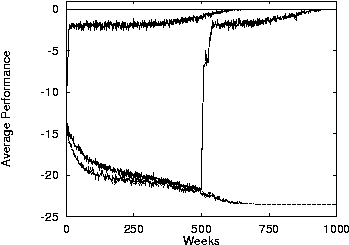
- With macro learning at 500 weeks on the middle curve (random
assignments).
- The random subworld-assignment jumps when macrolearning
happens.
8 Results
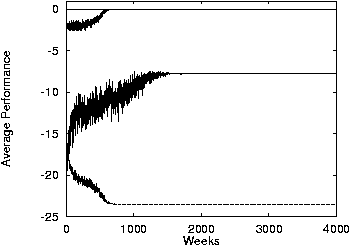
- Same as before but using a random payoff matrix.
- No macrolearning.
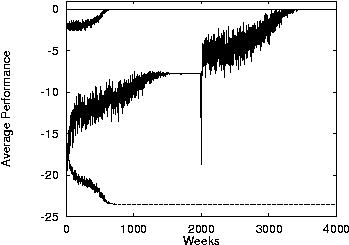
- With macrolearning at 2000 weeks.
- Results are similar to before except that the curves are
generally higher and there is a transient drop when
macrolearning happens.
9 Optimal Payoff Functions
- The second paper finds an even better payoff function.
- We define the aristocrat utility to be a measure
between the players' actual action and its average action.
- A player should use the AU as its payoff function to ensure
good alignment between its payoffs and the global utility.
- Unfortunately, doing so means that the player changes its
average action, thereby obviating the derivation process. There
are fixed-point solutions to this problem.
- However, it is much easier to assume so fixed utility that
does not depend on the player's, like WLU.
- WLU can be modified to make it more like AU (less
opaque) by clamping to a different set of actions.
10 El Farol Extension
- Instead of attending just one night, the players can attend
1..6 nights.
- They always attend consecutive nights.
- We let h={1,2,3,4,5,6} be a parameter for this game that
tells how many nights the agents should attend.
- A player's action is a 7-element binary vector, where 1
means the agent will attend that night and 0 means he will
not.
11 Wonderful Life Utilities
- We can define three new WL utilities to experiment
with.
- In WLU0 we clamp down to "never attend". It is
the same as before: l(xdn(S)) -
l(xdn(S) -1)
- In WLU1 we clamp down to "always attend". It is SUMd != dn l(xd(S)) - l(xd(s)-1)
- In WLUa we clamp down to the "average action"
which in this case is attending with probability 1/h each
night.
- SUMd l(xd(S)) - SUMd != dn l(xd(S) + h/7) - l(xdn(S) - 1 + h/7)
12 Results
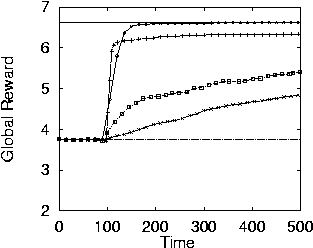
- Results for h=1 (one night attendance). The diamonds are
WLUa, the + are WLU0, the squares are
WLU1, and the x is G.
- WLUa does better than any other.
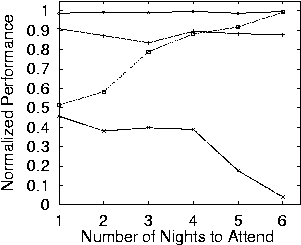
- WLUa does well no matter how many nights the
agents must attend. The other curves are not flat.
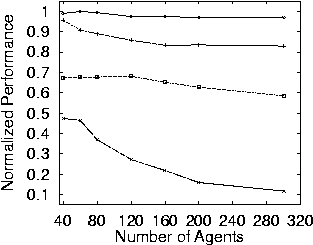
- The AU-based utility also scales well.
13 Conclusion
- The math in these papers can be hard to understand because
it uses physics notation and tries to be very general.
- However, the two main results are easy to understand and
apply. When choosing a reward function for a
reinforcement-learning MAS, you should:
- Use the wonderful life utility. That is, give each agent
a reward the is the difference of the global reward given
the current state and the global reward if the agent had
done some other fixed action.
- Try to make that other fixed action the agent's "average
action"
- It remains to be seen how (or if) well COIN can be applied
to more complex domains.
URLs
- General Principles of Learning-Based Multi-Agent Systems., http://jmvidal.cse.sc.edu/library/wolpert99b.pdf
- Optimal Payoff Functions for Members of Collectives., http://jmvidal.cse.sc.edu/library/wolpert01a.pdf
This talk available at http://jmvidal.cse.sc.edu/talks/coin/
Copyright © 2009 José M. Vidal
.
All rights reserved.
28 May 2002, 08:40AM